Creating a Practical and Automatic Server and Data Backup Solution
- Matt Zaske
- February 27, 2023
- 8 minutes
If you had disk/storage failure (on any of your important devices/things/places), would you be "up the creek?"
For many folks, the answer to that question is "absolutely."
A number of years ago I gave a "Wellness Program" presentation on preserving one's digital legacy. If memory serves, I had a full room for that session (about 40 people). While most of my focus was on things related to survivor access to accounts and storing information in a password manager with critical account/credential information also stored on paper in a secure location (such as safety deposit box), a portion of the presentation spoke to electronic document retention and backups. I mentioned several options for personal document storage "in the cloud" including my own use case at that time: Amazon Cloud Drive.
Services Change and Evolve
I have long appreciated and enjoyed the simplicity of Amazon Cloud Drive's service, specifically the multi-device synchronization and, with the drive sync (now Photos) desktop app, how trivial it was to keep a synchronized backup of local material in a cloud/offsite location.
But in fall 2022, Amazon announced the end of life for "document" (not photo or video) storage on the platform, which meant I needed to find an alternative way to retain some "off device" backup for personal documents, etc., and to do so before the end of 2022 when new material would no longer be uploadable. This was a huge bummer for me, and I still disagree with the move. I did some cursory looking at other cloud "drive" services and had narrowed it down to two options, not named here as I haven't actually moved forward with either at this time.
But What About Servers and Services?
In late December, I upgraded servers to Ubuntu 22.04. In the process, I realized that while I had a pretty solid backup solution (though it was going away) for documents, I was devoid of a meaningful backup plan for several other things in my servers and services portfolio. I had automatic VM snapshots for key Internet-facing servers, and automatic backups of some services thanks to a plan with Installatron, but these were mostly "in place" solutions assuming the "least interruption" sort of need: a live server is available, but the app/service needs to be reverted.
On my local network, this meant the configuration for things like Pi-Hole, Home Assistant, and OctoPrint. Some services I've put considerable effort into curating and losing them outright would be a Really Bad Day. Since I was in the mindset of server stuff I figured this upgrade was just as good a time as any to evaluate what I had, what should be backed up, and most importantly identifying where data should be replicated.
Avoiding a Complexity Rabbit Hole
One of the reasons I hadn't really looked into this boiled down to analysis paralysis. There were a lot of moving parts and disparate things, and it's super easy to get into the "perfect is enemy of good" mindset, which also brings its little brother "overly complicated" for the ride.
I started this most recent journey by drawing out what I had (in "bubbles") and where it was ("in boxes"). Since I have Internet-facing servers (web applications, etc.), private local network servers (services), and my "main" computer (documents) in play, the diagram gets a little complex, but seeing it drawn out added a level of clarity:
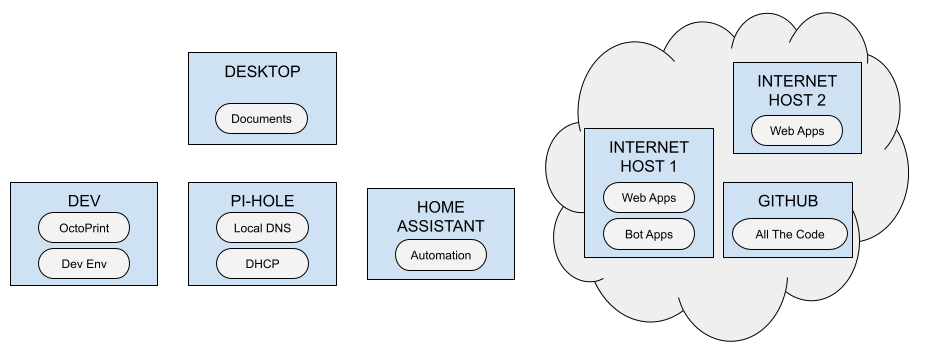
Three (and a half) Locations, Eventually
I settled on what I believe is a good balance with regard to simplicity and access when viewed through the lens of "likelihood:"
- Web app backups (generated via Installatron) would replicate to my main computer;
- Web app configurations/apps not maintained via Installatron would replicate to my main computer (or to Github if appropriate for the "thing");
- Server config "runbooks" (of sorts) and other base configurations would be stored in Github;
- Local services (Pi-Hole/Home Assistant backups, etc.) would replicate to my main computer;
- My document repository (main computer) would replicate to my local "dev" server; and
- When I settle on a cloud drive solution/plan, most everything above will also replicate to it as a "secondary" backup.
The idea behind all of this is that, due to power and other protections in place on my equipment and network, the likelihood of needing high-availability backup via cloud service is quite low. Sudden single disk failure is the most likely problem in scope. The cloud part becomes the "last mile" to walk. This means that should a recovery be necessary from the cloud service it's probably because Something Really Gnarly has happened. I wouldn't need to rely on the cloud service for a "run of the mill" recovery, which means it's more feasible to add an encryption step to anything replicating there where appropriate, becoming a "cold storage" location.
This consolidates risk to two local machines: my main computer and my local "dev" server. I chose these two since they are the most robust at the moment. The tenet is about protecting Future Me from losing everything. Ultimately it "looks" like this, where the solid lines indicate scheduled data movement and the dotted lines indicate stuff that would be in 'sync' via GitHub:
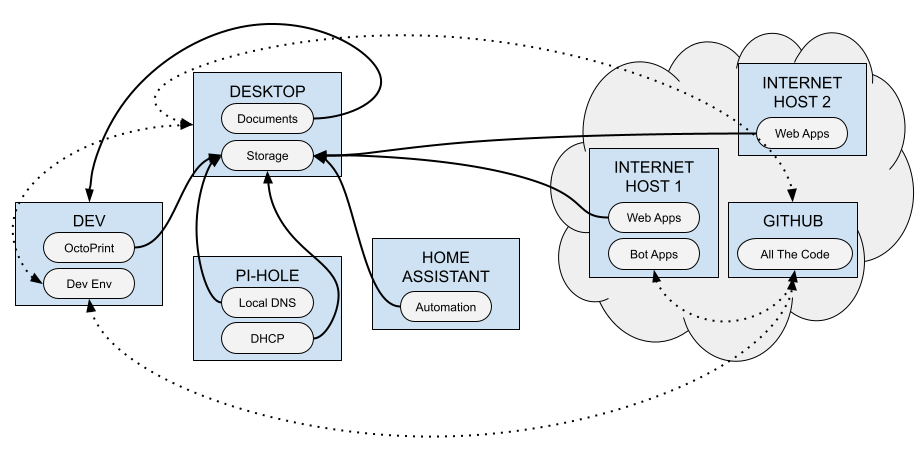
Great, but How Does It Work?
The simplicity in this solution is that it's all automated with basic bash scripts and triggered with cron. Since I have WSL on my main computer and everything is set up for key authentication, connection mechanics are all handled without any passwords and are easily scriptable. WSL 2 also affords better visibility into my Windows partitions so I can work with data "outside" of Linux. There are three ways I set up to move data between machines, and two ways I manage the destination's storage/retention:
Replicating to Other Hosts
Depending on how backups are generated and maintained at the source, I use one of the following mechanisms. Fundamentally they all do the same thing; each with its nuance.
SCP: Just grab copies of it all...
/usr/bin/scp -q remote.host.tld:/path/to/source/backup/*.tgz /path/to/replication/archive
SFTP: When it's good to clean up after yourself...
/usr/bin/sftp remote.host.tld >> /dev/null 2>&1 << EOT
cd /path/to/source/backup/
lcd /path/to/replication/archive
get -p *.tgz
rm *.tgz
exit
EOT
RSYNC: When you want to mirror all the content....
/usr/bin/rsync -aq --delete remote.host.tld:/path/to/source/backup/ /path/to/replication/archive
Since I use these commands in bash scripts I have output piped to /dev/null or use quiet switches. It's important to test these commands before setting them to be quiet, as it's much more difficult to discern runtime problems without notifications.
Cleaning Up/Managing Backup Retention
For non-mirrored options obtaining backups (where I don't use rsync), the storage demand would grow indefinitely on the replication host, Since these are "point in time" backups, in most cases I use a 30-day retention window because it's not practical to store anything longer than that window. Your mileage may vary, though. For me, not everything is backed up daily (some are weekly or on another schedule) but this simple one-liner is fabulous for cleaning up the storage regardless of the window in question:
/usr/bin/find /path/to/replication/archive -type f -mtime +30 -delete
It will automatically delete any file at the replication path with a modified date 30 days ago (or older). I run these cleanup jobs once a week to keep things tidy.
Longer-Term Maintenance
Most cron jobs run on one machine so there's not much hunting around for or syncing jobs. There are some bits on remote machines for generating the tarballs, especially for services that don't generate their own backups, though. What I like about this solution is, while certainly imperfect, it handles everything automatically and in a time of need I can still get to the data or a recent backup without having to get into a safety deposit box. I still do a "nuclear option" backup once a year or so with flash media, but that's far out of scope for this post.
In the absence of having and maintaining a NAS device, something "relatively simple" (albeit with many parts) like this works for what I need, when I need it, and matches the risk tolerance I've got for the data/stuff along with balance for the likelihood of needing to restore. There's more moving parts than I'd prefer, and I expect to refine this in more elegant ways once I settle on a cloud storage service. But to my motto of "Is it better than yesterday?" the answer with a solution like this is "Absolutely, yes." Remember: it doesn't have to be perfect—it just needs to be in place.
Recent Posts
Past Speaking Engagements
I was a speaker at MMSMOA, May 3-7, 2026!

I was a speaker at MMS Music City Edition, October 12-15, 2025!

I was a speaker at TCSMUG Autopilot/OSD Day, July 15, 2025!
![]()
I was a speaker at MMSMOA, May 4-8, 2025!
I was a speaker at BrainStorm K20 Wisconsin Dells, March 9-11, 2025!

I was a speaker at MMS Flamingo Edition, October 20-23, 2024!

I was a speaker at TCSMUG OSD Day, July 31, 2024!
![]()
I was a speaker at NWSCUG, July 19, 2024!
![]()
I was a speaker at MMSMOA, May 5-9, 2024!
I was a speaker at BrainStorm K20 Wisconsin Dells, March 10-12, 2024!
I was a speaker at MMS Miami Beach, October 29-November 1, 2023
